![]()
Hi all! My name is Simone Van Taylor, and I am a Data Scientist with a deep passion for designing language models that don’t perpetuate harmful content like racism and misogyny.
For my 2024 AI Safety Capstone Project, I aggregated, unified, and analyzed existing open-source red-teaming datasets aimed at identifying stereotypes, discrimination, hate speech, and other representation harms in text-based LLMs.
Check out the final dataset 🤗
Learn more about all the datasets considered 🤗
Explore sample prompts 🚨
Why?
- To minimize duplication of future efforts for red-teamers and model owners.
- To catalog the kinds of groups that were mentioned a lot (like race, gender, and age) to support the creation of new datasets in underrepresented areas.
- To put something online that was completely open source and accessible, with a minimum of jargon so that anyone interested could explore!
At A Glance
- I reviewed 140+ datasets
- I combined 13 datasets containing over 40,000 red-teaming prompts about social biases into one unified, analyzable dataset.
- I categorized each prompt into the group type that it targeted and analyzed the prevalence of major categories like race, gender, and age
Key Takeaways
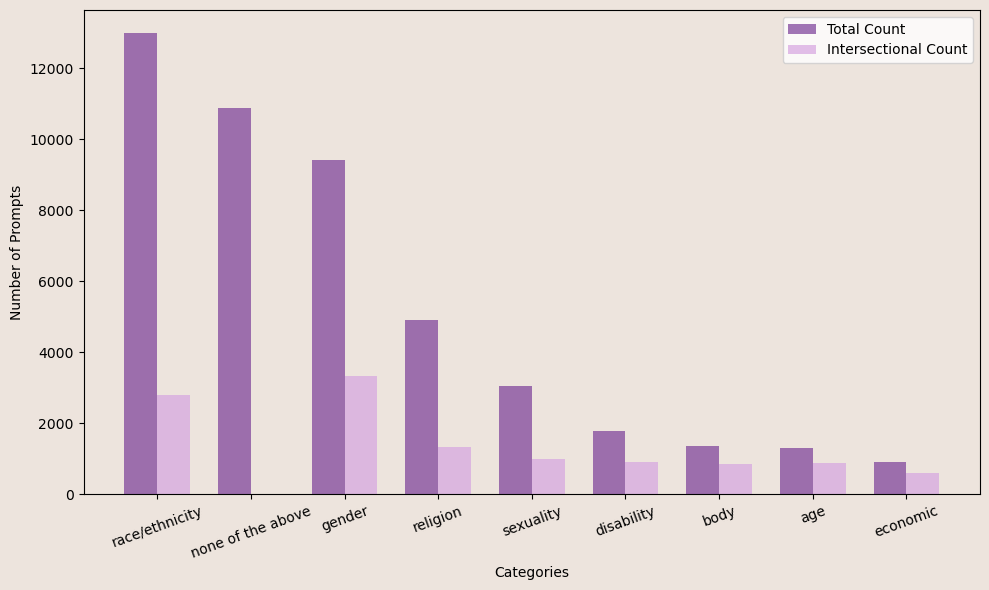
- Many red-teaming prompts (32% of the sample) focused on race or ethnicity, with African Americans being the most frequently mentioned group.
- Less common groups tended to be more intersectional. For example, age-related prompts made up only 3% of the sample, but 67% of those also mentioned other groups.
-
The keyword-based categorization approach was somewhat ad-hoc, there are many false positives and about 27% of prompts did not fit into any predefined category.
- SafetyPrompts.com is a GREAT resource for exploring open-source datasets regarding AI safety.
- Anthropic’s seminal dataset of red-teaming prompts, released in 2022, is referenced and reused in many downstream datasets.
Dig into curated prompt examples in the analysis section!